Improvements to spellchecker
The next key part of my Google Summer of Code Project, the improvements to the existing spellchecking system provided by libindic is getting ready.
Proposed Additions
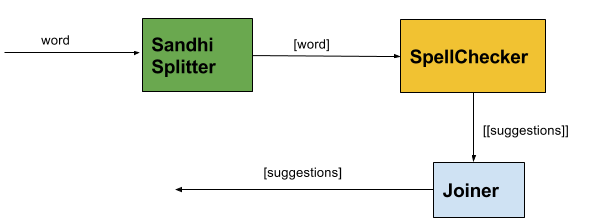
diagram in original proposal
Code
I’ve created a toy code with the promised functionality, which can easily be converted into the actual code.
This requires spellchecker and sandhisplitter to be installed.
Here’s the snippet:
# -*- coding: utf-8 -*-
from __future__ import absolute_import, division
from __future__ import print_function, unicode_literals
from spellchecker.core import Spellchecker
from sandhisplitter import Sandhisplitter
from itertools import product
class SEnhanced:
def __init__(self):
self.sc = Spellchecker()
self.sp = Sandhisplitter()
def suggest(self, word):
if self.sc.check(word):
return [word]
return self.suggest_with_split(word)
def suggest_with_split(self, input_word):
words, sps = self.sp.split(input_word)
corrections = []
correct = True
for word in words:
if not self.sc.check(word):
correct = False
candidates = self.sc.suggest(word)
corrections.append(candidates)
else:
corrections.append([word])
suggestions = []
if not correct:
# Cross corrections.
possibilities = product(*corrections)
for element in possibilities:
joined = self.sp.join(element)
suggestions.append(joined)
else:
suggestions = [input_word]
return suggestions
if __name__ == '__main__':
import sys
from io import open
s = SEnhanced()
testfile = open(sys.argv[1], 'r', encoding='utf-8')
outfile = open(sys.argv[2], 'w', encoding='utf-8')
for line in testfile:
word = line.strip()
outfile.write(word+":\n")
for suggestion in s.suggest(word):
outfile.write('\t'+suggestion+'\n')Input file
Now, after I give the following as input:
എന്തൊക്കെയോ
ആദ്യമെത്തി
കൊള്ളാമെന്ന്
എവിടെനിന്നോ
അവനെക്കൊണ്ട്
എത്രയൊക്കെയായാലും
മത്രമായ
കണ്ടുകണ്ടങ്ങിരിക്കുംജനങ്ങളെ
എന്തനോവേണ്ടി
ഉല്ക്കൊണ്ടുOutput
I get the following output:
എന്തൊക്കെയോ:
എന്തൊക്കെയോ
ആദ്യമെത്തി:
ആദ്യമെത്തി
കൊള്ളാമെന്ന്:
എവിടെനിന്നോ:
എവിടെനിന്നോ
അവനെക്കൊണ്ട്:
അവളെക്കൊണ്ടു
എത്രയൊക്കെയായാലും:
എത്രയൊക്കെയായാലും
മത്രമായ:
മകരമായ
മങ്കമായ
മതമായ
മതവുമായ
മതിരയായ
മതേതരമായ
മത്തയായ
മത്തെയായ
മത്തായ
മത്സരയായ
മത്സരമായ
മദ്യമായ
മധുരമായ
മധ്യമായ
മന്ത്രമായ
മന്ദമായ
മന്നമായ
മരമായ
മറ്റമായ
മല്സരമായ
മഷ്രൂമായ
മഹത്തമായ
മഹത്വമായ
മാതാരമായ
മാത്യമായ
മാത്രയായ
മാത്രമായ
മാത്രോയായ
മിത്രയായ
മിത്രമായ
മിത്രായായ
മുത്തമായ
മൈത്രിയായ
മൊതിരമായ
മൊത്തമായ
മോതിരമായ
കണ്ടുകണ്ടങ്ങിരിക്കുംജനങ്ങളെ:
എന്തനോവേണ്ടി:
എന്തിനുവേണ്ടി
ഉല്ക്കൊണ്ടു:The function suggest returns an empty list if the word is incorrect and no suggestions have been found. If the word is correct, it simply returns a singleton list with the word in it. Otherwise, it contains the possible suggestions.
Of course, there are limitations. But this is definitely an improvement on the previous spellchecker which used to give wrong spelling and no outputs on many of these words.
What next?
A polished version of this was what I had in mind when I started with the project. There has been developments in the spellchecker to handle inflections, the source being hosted at balasankarc/spellchecker. I’ll have to see how well I can use that and make the spellchecker even better.
Also, the next question is where this code should be merged in. The code is written using the existing API and operates one layer above both. As the modules in the improve, the outputs here also will improve.
(Comments disabled. Email me instead.)