The sandhi-splitter module
Another milestone of my Google Summer of Code coding period is close - end of the first coding period and mid term evaluations. And here is the log of the journey so far.
Big picture.
Given below is what was proposed as part of the sandhi-splitter module in my draft.
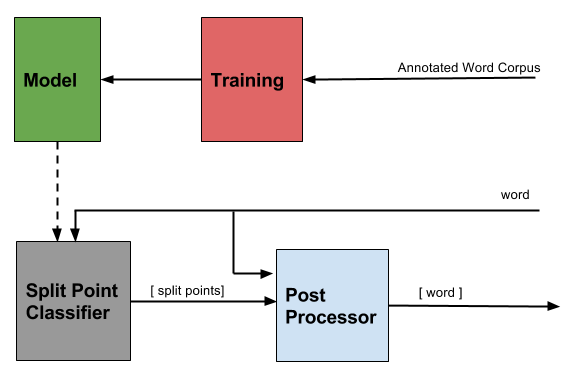
uml(sort of) - diagram
The previous post was regarding the training, model and the split point classifications part in the module. The work done after that involves the postprocessor, integrating the components together and writing a few helper scripts for people who might want to extend this functionality to another language.
A rough mapping of these to the source files in the repo would be:
sandhisplitter/models/*- Stored modelsmodel.py- Model object, to access stored models, uses trie.splitter.py- Split Point Identificationpostprocessor.py- Post Processingtrain.py- Helper Script for the training partbenchmark_model.py- Helper script to determine performancetrie.py- The trie structure, used of model.util.py- as the name suggests.__init__.py- integrating multiple components throughWrapperclass.
The data is organized in the data folder and tests are in sandhisplitter/tests.
I’ve followed a bottom-up approach in building this software, starting with the basic blocks and now integration into the entire whole. First I wrote the trie, then went ahead to write the training script and model. After that the split point identification part was added, following which the postprocessor and wrappers were added. A helper script to benchmark a model based on test data was written after that.
Most of the code is written to meet the functionality requirements first. I’m proud that I’ve maintained DRY principles to a large extent. PEP-8 compliance and decent coverage have maintained and the tests enforce them too. One good thing I’ve picked up from being exposed to the developer perspective is the importance of unit tests. One great advantage I see is that it reminds you to make sure things don’t break while you modify them later.
Hiccups
This period has made me realize that I’m not even in an intermediate level in my knowledge of git. I’ve been doing the delete reset thing till a while back. This time I’m reading proper documentation on rewriting history, still screwing up, fixing things after. Sometimes it gets so complicated that delete-clone again saves more time.

xkcd-1597: git
My PR is still awaiting merge due to my own doings. I’ll just put this comic here and hope you understand.

xkcd-1296: git-commit
Also worth mentioning is some mix up with terminologies. Testing part from the learning terminology got mixed up with unit-tests and created a lot of confusion.
(Comments disabled. Email me instead.)