This post is an experiment killed rather early while I was looking into interpretability of learned transformer representations during my Masters. The post is added to my personal blog on 2020 August 06, but the date of the original post in my blog preserved. It’s written in the fashion of somthing like a paper. A better work I found after dropping my pursuits surrounding the problem is Investigating Multilingual NMT Representations at Scale, by a group in Google.
Introduction
In this work, we investigate
- Sentence representations from a multilingual neural machine translation model.
- We explore the possibilities of re-use and transfer of these learnt embeddings.
Methodology
Datasets and Training
We train a multilingual model with joint encoder, decoder and shared embeddings between both as per Johnson et al. (2017) on a large compiled corpus consisting of IIT-Bombay Hindi English Parallel Corpus (IITB-hi-en) [Kunchukuttan et al. (2018)], Indian Languages Corpora Initiative (ILCI) [Jha (2010)], WAT-Indic Multi Parallel Corpus (WAT-ILMPC) [Nakazawa et al. (2018)]. The test sets of both IITB-hi-en and WAT-ILMPC are left out of training and the evaluation scores on these are reported below. We use a compilation of validation sets from the two datasets for monitoring validation loss.
| srcs | hi | en |
|---|---|---|
| en | 20.46 | 100.00 |
| hi | 100.00 | 22.91 |
For evaluating multilingual embeddings we use the Mann Ki Baat dataset as an unseen dataset, and ILCI corpus from the training dataset. The details of this dataset are described in the table below. We use 3348 samples aligned across each language form Mann Ki Baat and 50K from ILCI corpus. The BLEU scores on Mann Ki Baat are provided below.
| srcs | bn | en | hi | ml | ta | te |
|---|---|---|---|---|---|---|
| bn | 99.87 | 15.20 | 14.43 | 8.15 | 3.85 | 7.35 |
| en | 9.50 | 100.00 | 15.37 | 8.71 | 4.60 | 8.20 |
| hi | 11.97 | 21.79 | 99.20 | 9.09 | 5.83 | 9.49 |
| ml | 6.85 | 12.00 | 9.84 | 99.90 | 3.37 | 7.32 |
| ta | 3.51 | 6.92 | 5.86 | 4.06 | 99.91 | 3.63 |
| te | 6.99 | 11.06 | 9.54 | 8.00 | 3.59 | 99.74 |
| ur | 0.00 | 0.00 | 19.55 | 0.00 | 0.00 | 0.00 |
Encoded Representations
To obtain fixed-dimensional sentence representations for a variable length input sequence, we follow Zhang et al. (2018) to use a concatenation of max-pooled features over time and the mean across the time-steps each individually L2 normalized. Below, we detail an ablation study by varying possibilities and found that this representation gave best results. Once we reaffirm the extracted features work best among those proposed, we attempt to visualize the Mann Ki Baat dataset in lower dimensions to seek what properties are strong in the encoded representations at a macro scale.
Nearest Neighbours
First, we attempt to analyze over the test set for a give source and target in languages \(xx\), \(yy\) respectively, embeddings generated to translation to which languages \(\hat{xx}\), \(\hat{yy}\) respectively works the best. To this end, we collect the embeddings from encoder representations for each source attempted to translate to a language. For each sample, we obtain the nearest neighbours in other languages using faiss1 (Johnson et al., 2019).
For the above experiment, we report the overall precision@1 over each pair of languages in the table below. The columns represent the source whose language of the sample whose nearest neighbour is being retrieved. The row indicates the target language samples which are being queried. Precision is computed in the information retrieval sense as
\[ \mathrm{p@k} = \frac{\#(\mathrm{relevant} \cap \mathrm{retrieved})}{\# \mathrm{retrieved}} \]
A retrieval is considered relevent if it belongs to the same multilingual sample as the query.
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.317 | 0.483 | 0.306 | 0.173 | 0.310 |
| en | 0.332 | 1.000 | 0.471 | 0.243 | 0.106 | 0.199 |
| hi | 0.491 | 0.513 | 1.000 | 0.344 | 0.200 | 0.325 |
| ml | 0.286 | 0.199 | 0.292 | 1.000 | 0.151 | 0.260 |
| ta | 0.113 | 0.071 | 0.139 | 0.119 | 1.000 | 0.118 |
| te | 0.271 | 0.181 | 0.270 | 0.268 | 0.153 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.236 | 0.426 | 0.266 | 0.140 | 0.256 |
| en | 0.245 | 1.000 | 0.443 | 0.168 | 0.075 | 0.153 |
| hi | 0.420 | 0.428 | 1.000 | 0.270 | 0.164 | 0.261 |
| ml | 0.260 | 0.152 | 0.255 | 1.000 | 0.133 | 0.247 |
| ta | 0.120 | 0.067 | 0.148 | 0.117 | 1.000 | 0.122 |
| te | 0.246 | 0.144 | 0.253 | 0.243 | 0.134 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.110 | 0.323 | 0.186 | 0.090 | 0.186 |
| en | 0.168 | 1.000 | 0.316 | 0.110 | 0.046 | 0.104 |
| hi | 0.343 | 0.278 | 1.000 | 0.202 | 0.116 | 0.196 |
| ml | 0.194 | 0.081 | 0.193 | 1.000 | 0.105 | 0.191 |
| ta | 0.071 | 0.027 | 0.084 | 0.089 | 1.000 | 0.088 |
| te | 0.164 | 0.066 | 0.163 | 0.174 | 0.097 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.245 | 0.412 | 0.246 | 0.136 | 0.266 |
| en | 0.290 | 1.000 | 0.409 | 0.188 | 0.079 | 0.160 |
| hi | 0.452 | 0.447 | 1.000 | 0.290 | 0.165 | 0.284 |
| ml | 0.259 | 0.149 | 0.251 | 1.000 | 0.125 | 0.239 |
| ta | 0.105 | 0.053 | 0.116 | 0.099 | 1.000 | 0.108 |
| te | 0.248 | 0.140 | 0.240 | 0.222 | 0.122 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.305 | 0.457 | 0.280 | 0.155 | 0.284 |
| en | 0.304 | 1.000 | 0.433 | 0.222 | 0.096 | 0.178 |
| hi | 0.459 | 0.489 | 1.000 | 0.317 | 0.180 | 0.299 |
| ml | 0.263 | 0.188 | 0.272 | 1.000 | 0.133 | 0.234 |
| ta | 0.103 | 0.070 | 0.128 | 0.104 | 1.000 | 0.106 |
| te | 0.251 | 0.172 | 0.253 | 0.244 | 0.135 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.290 | 0.479 | 0.300 | 0.170 | 0.299 |
| en | 0.307 | 1.000 | 0.497 | 0.213 | 0.100 | 0.192 |
| hi | 0.471 | 0.488 | 1.000 | 0.313 | 0.200 | 0.303 |
| ml | 0.299 | 0.189 | 0.299 | 1.000 | 0.152 | 0.281 |
| ta | 0.144 | 0.085 | 0.176 | 0.132 | 1.000 | 0.138 |
| te | 0.286 | 0.184 | 0.295 | 0.274 | 0.157 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 1.000 | 0.152 | 0.388 | 0.234 | 0.123 | 0.238 |
| en | 0.234 | 1.000 | 0.378 | 0.155 | 0.062 | 0.141 |
| hi | 0.411 | 0.355 | 1.000 | 0.257 | 0.150 | 0.253 |
| ml | 0.246 | 0.115 | 0.241 | 1.000 | 0.134 | 0.237 |
| ta | 0.094 | 0.037 | 0.107 | 0.107 | 1.000 | 0.107 |
| te | 0.213 | 0.091 | 0.205 | 0.215 | 0.122 | 1.000 |
| bn | en | hi | ml | ta | te | |
|---|---|---|---|---|---|---|
| bn | 0.285 | 0.110 | 0.144 | 0.103 | 0.057 | 0.091 |
| en | 0.109 | 0.362 | 0.151 | 0.092 | 0.044 | 0.072 |
| hi | 0.143 | 0.144 | 0.309 | 0.108 | 0.067 | 0.092 |
| ml | 0.098 | 0.077 | 0.089 | 0.298 | 0.050 | 0.079 |
| ta | 0.042 | 0.032 | 0.050 | 0.041 | 0.259 | 0.038 |
| te | 0.091 | 0.070 | 0.084 | 0.085 | 0.052 | 0.284 |
(But the above is among very little samples. Perhaps I should index with larger representations, to well establish the Mann Ki Baat ones still come close.)
Embedding and visualizing in lower-dimensions
In the below images, we illustrate the lower-dimension projections using t-SNE of the sentence embeddings from Mann Ki Baat dataset. We first do a PCA to reduce the dimensions to 20, followed by t-SNE on 2-dimensions.
The representations are built from multilingual samples of Mann Ki Baat, each entry having attributes identified by the unique tuple source, target and sample-id. Multiple language samples of the same content are indexed by same sample-id.To observe which axis among these forms the grouping which make most sense - we fix a few, while keeing the others varying.
Note that our methods of embedding to a 2D space of all samples are unsupervised. We proceed to color the resulting datapoints according to the labels extracted as source, target, sample-id and combinations of the same.
Target Space
In the first case, we color the projections using the target language attribute.
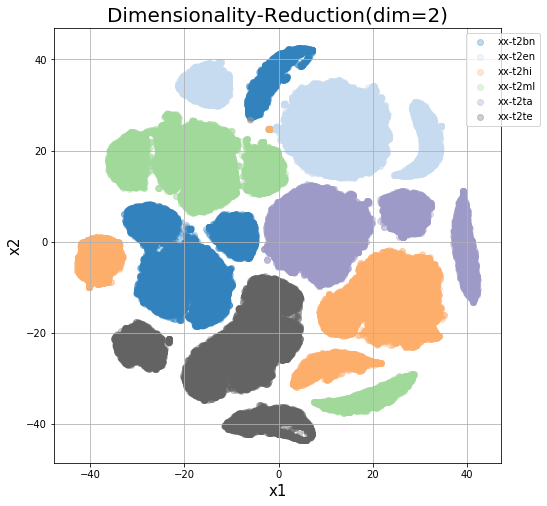
The best grouping is obtained on the target space, implying each the encoder representations group same target language samples together. The results are in agreement with the findings of Johnson et al. (2017). We’ve possibly learnt the hard way that these sentence representations aren’t that reusable for vector space comparisons as cross lingual retrieval mechanisms. Another interesting thing to note here is that each representations contain the same shapes for all languages.
(TODO: This could suggest that there exists a matrix which can be obtained by solving the Procustes problem similar to Lample et al. (2018) to get a rotation matrix. Update: Google’s submission did SVCCA, which might be more apt a choice.)
Source language space
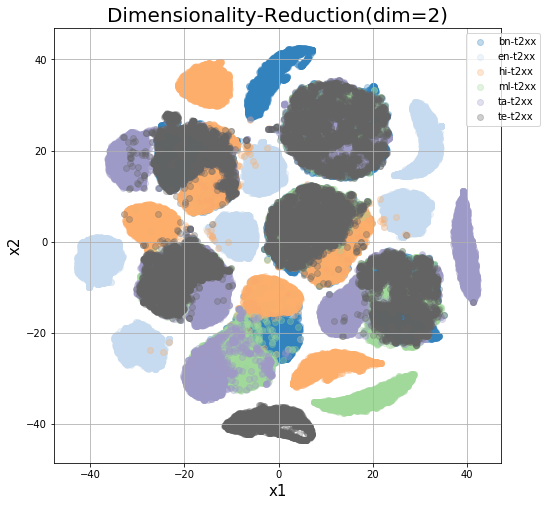
The source language boundaries still form some subclusters, although not as the target. For a better look, we try to view the source samples embedded for a fixed target language. Given below are encoded representations while attempting to translate to English and Hindi as indicated in the graphs below.
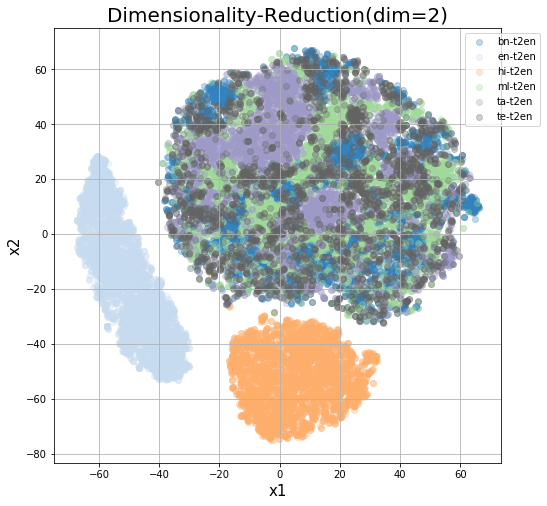

It’s observable above that en-t2en directly maps to hi-t2hi and en-t2hi somehow is similar to hi-t2en. But the samples not being overlayed on top of each other is still a problem, as attempts to translate to a single language isn’t likely to produce robust embeddings for cross-lingual sentence representations.
Colored by source and target
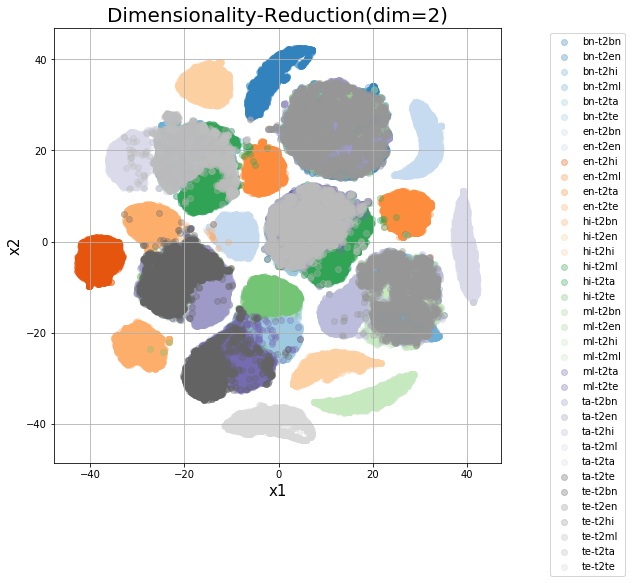
The above is a more fine-grained view of the clusters, considering src-tgt as the labels and coloring accordingly.
Same concepts - different language.
Next, we encode all sentences to translate to Hindi (xx-t2hi). Since here points are closer in terms of source language rather than similarity in meaning or content, we can conclude that even at a microscopic scale, we’ll need further refinements to use these embeddings as multilingual sentence representations.
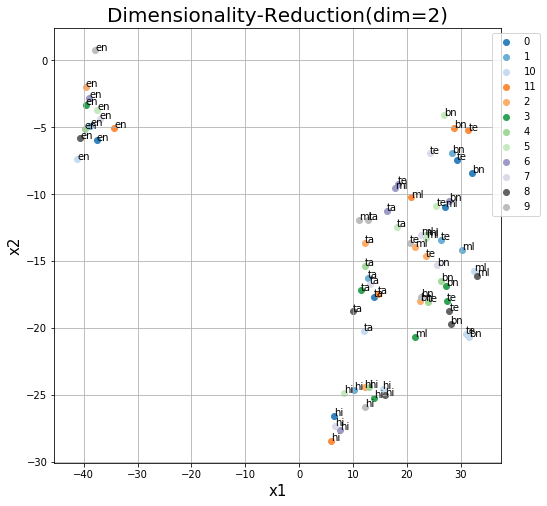
Above, we check if multilingual closeness exists, and turns out it doesn’t. English and Hindi seems to have their own close spaces, while the others are a bit cluttered. This also seems to correlate with the size of data we have in each languages, the degree of intra-language closeness and inter-language separation. Perhaps once the data matches up in other languages, we could see how this evolves.
Literature Survey
Multilingual Translation
Johnson et al. (2017) introduced Multilingual Neural Machine Translation switching target language based on a token prepended to the input sequence. This simple method demonstrated major improvements and zero-shot capability in translation. If the parameters of the encoder and decoder and respective embeddings are shared among all languages, a consequence is that the encoder outputs become cross-lingual representations of the concept in the source language.
Feature Extraction
Zhang et al. (2018) adapts the encoder architecture from the transformer model proposed by Vaswani et al. (2017) as sentence representation learning models. They however investigate the utility through downstream tasks constructing the sentence-representations through an autoencoding objective on the sentences. Schwenk and Douze (2017) uses max-pooled features across timesteps, which seems to be working out well for their use cases.
Mining Parallel Pairs
Past works in multilingual mining have made significant use of representations arising out of translation task [Schwenk and Douze (2017), Schwenk (2018), Artetxe and Schwenk (2019a), Artetxe and Schwenk (2019b)]. Since mining is enabled by the ability to query a sample in the vector space induced by translation, most of these work becomes relevant to the likes of cross-lingual sentence embeddings.
Schwenk and Douze (2017) proposes the following desired properties: (i) multilingual closeness, (ii) semantic closeness, (iii) preservation of content, (iv) scalability to many languages. Schwenk (2018) uses cosine similarity, for the same representation and applies it to the BUCC task. They conclude the distance can be used in confidence estimation or to filter backtranslations. Artetxe and Schwenk (2019a) strips the encoder inputs off source or target language information, having embeddings corresponding to target fed to the decoder instead, thereby providing “encoded-representations” of the sequence in a common space.
- The error rates reported are low. Quite unsure if our embeddings on Mann Ki Baat matches up to this degree. The nearest neighbour retrieval precision presented before as proxy supports this. Uses vanilla seq2seq NMT models (possibly Bahdanau et al. (2014) or Luong et al. (2015)).
- It may perhaps be interesting to look at the t-SNE dynamics of this modified network.
Evaluations
The XNLI Dataset [Conneau et al. (2018)] seems to be used by people in the community for benchmarking multiingual embeddings [Artetxe and Schwenk (2019b)]. Hindi (hi) seems to be the only reported Indian Language in the testing set.
Often, mining parallel text from news corpus and training a translation system to obtain better BLEU seems to be an assertion in favour of better mining methods. If the representations are robust and performing well, this could indicate their success.
Conclusion and Future Work
Artetxe and Schwenk (2019b) seems to be a good way to go to generate sentence embeddings, but requires training from scratch and some modifications to pytorch/fairseq.
References
Mikel Artetxe and Holger Schwenk. 2019a. Margin-based parallel corpus mining with multilingual sentence embeddings. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 3197–3203.
Mikel Artetxe and Holger Schwenk. 2019b. Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and beyond. Transactions of the Association for Computational Linguistics, 7:597–610.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. XNLI: Evaluating cross-lingual sentence representations. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2475–2485.
Girish Nath Jha. 2010. The TDIL Program and the Indian Language Corpora Intitiative (ILCI). In LREC.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data.
Melvin Johnson, Mike Schuster, Quoc V Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, and others. 2017. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Transactions of the Association for Computational Linguistics, 5:339–351.
Anoop Kunchukuttan, Pratik Mehta, and Pushpak Bhattacharyya. 2018. The IIT Bombay English-Hindi Parallel Corpus. In Proceedings of the eleventh international conference on language resources and evaluation (lrec-2018).
Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word translation without parallel data. In International conference on learning representations.
Minh-Thang Luong, Hieu Pham, and Christopher D Manning. 2015. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
Toshiaki Nakazawa, Katsuhito Sudoh, Shohei Higashiyama, Chenchen Ding, Raj Dabre, Hideya Mino, Isao Goto, Win Pa Pa, Anoop Kunchukuttan, and Sadao Kurohashi. 2018. Overview of the 5th workshop on asian translation. In Proceedings of the 5th workshop on asian translation (wat2018).
Holger Schwenk. 2018. Filtering and mining parallel data in a joint multilingual space. In Proceedings of the 56th annual meeting of the association for computational linguistics (volume 2: Short papers), pages 228–234.
Holger Schwenk and Matthijs Douze. 2017. Learning joint multilingual sentence representations with neural machine translation. In Proceedings of the 2nd workshop on representation learning for nlp, pages 157–167.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
Minghua Zhang, Yunfang Wu, Weigang Li, and Wei Li. 2018. Learning universal sentence representations with mean-max attention autoencoder. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 4514–4523.